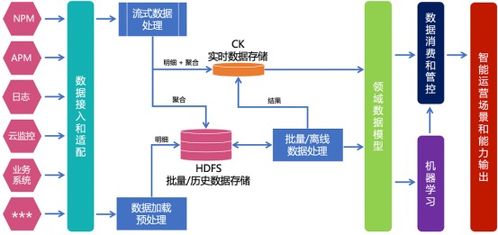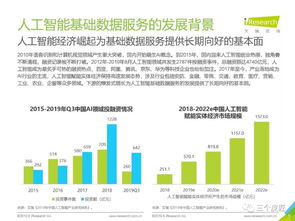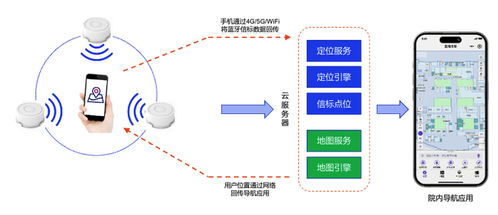
在當今數據驅動的時代,數據處理服務已成為企業運營與決策的核心支撐。為了高效、可靠地構建和交付數據處理系統,選擇合適的軟件開發模式至關重要。本文將探討四種主流的軟件開發模式——瀑布模式、敏捷開發、DevOps以及數據驅動的開發模式,并分析它們在數據處理服務中的具體應用、優勢與挑戰。
一、瀑布模式:結構化與可預測的數據處理項目
瀑布模式是一種線性順序的開發模型,將項目劃分為需求分析、系統設計、實現、測試、部署和維護等嚴格分離的階段。在數據處理服務中,瀑布模式適用于需求明確、變更較少的場景,如構建傳統的企業數據倉庫或執行一次性的大規模數據遷移項目。
應用場景:
- 合規性數據報告系統: 需求固定(如法規要求),需要詳盡的文檔和嚴格的驗證流程。
- 批處理流水線: 處理邏輯穩定,如每日的銷售數據匯總作業。
優勢: 階段清晰、文檔完備,便于管理預算和進度;適合對數據準確性與完整性要求極高、容錯率低的項目。
挑戰: 缺乏靈活性,難以應對數據處理中常見的需求變化(如新增數據源或分析維度);后期測試才發現問題可能導致返工成本高昂。
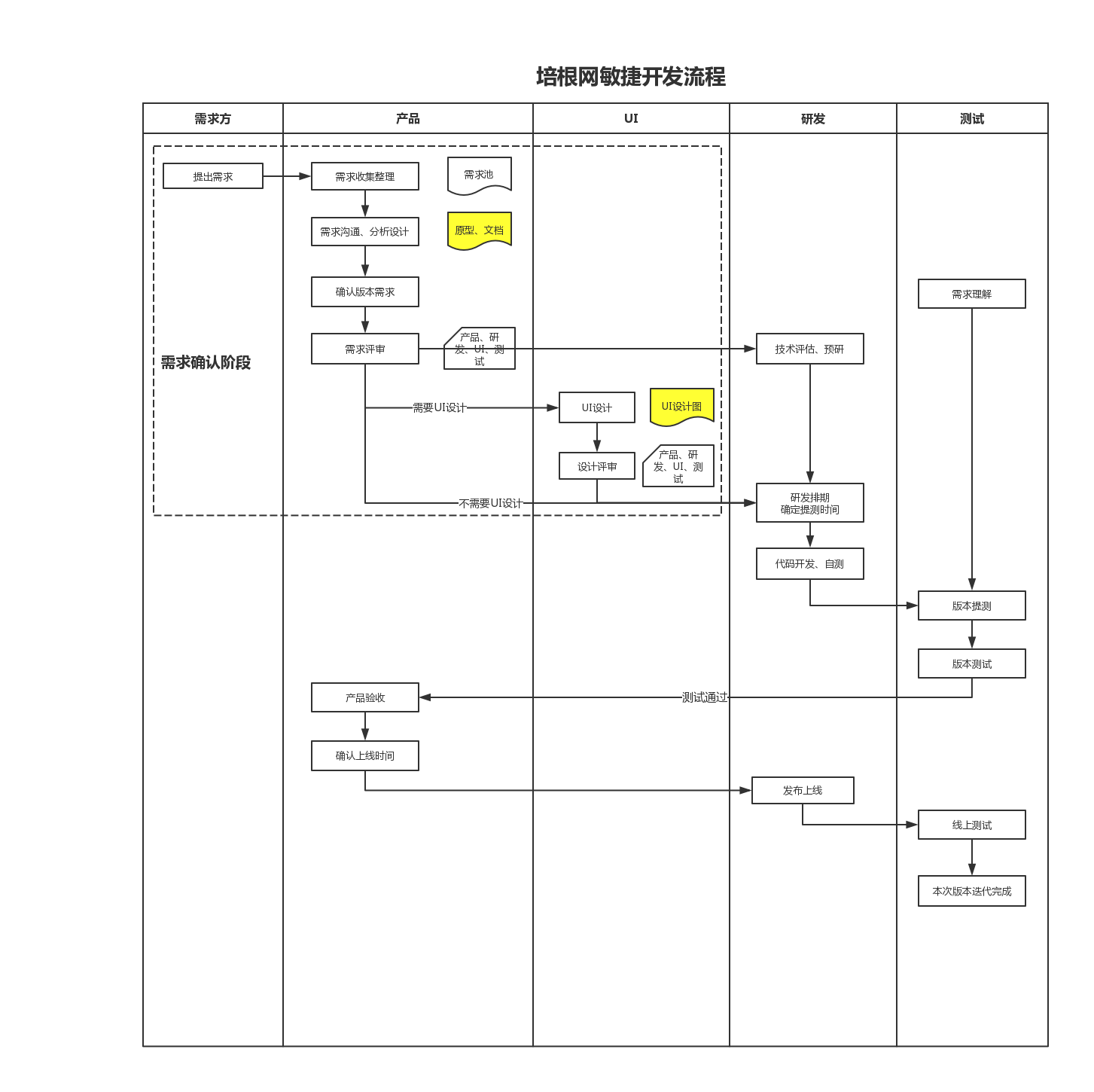
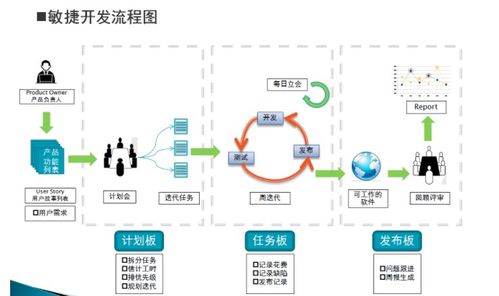
二、敏捷開發:迭代響應數據需求的快速演進
敏捷開發強調迭代、協作與快速交付,通過短周期的“沖刺”(Sprint)持續產出可工作的軟件。在數據處理服務中,敏捷模式特別適合探索性數據分析、用戶行為分析平臺等需求不斷演進的項目。
應用場景:
- 商業智能(BI)儀表盤開發: 業務用戶可能在使用中提出新的可視化或指標需求,需要快速迭代響應。
- 實時數據預處理服務: 隨著數據流模式的變化,需要不斷調整清洗和轉換規則。
優勢: 能夠靈活適應業務需求變化;通過持續交付最小可行產品(MVP),讓用戶盡早獲得數據價值,并提供反饋;提升團隊協作與問題響應速度。
挑戰: 對數據治理和架構一致性可能帶來挑戰,需要強有力的技術領導來維護整體數據模型的穩定;頻繁變更可能增加數據流水線的復雜性。
三、DevOps:實現數據處理服務的持續集成與交付
DevOps是一種融合開發與運維的文化與實踐,旨在通過自動化實現持續集成(CI)、持續交付(CD)和持續監控。對于數據處理服務,這意味著能夠自動化數據流水線的構建、測試、部署和監控。
應用場景:
- 云原生數據平臺: 使用容器化(如Docker)和編排工具(如Kubernetes)動態部署和管理數據處理微服務。
- 機器學習模型訓練流水線: 自動化從數據抽取、特征工程到模型訓練、評估和部署的全流程。
優勢: 極大提升部署頻率和可靠性;通過基礎設施即代碼(IaC)確保數據環境的一致性;快速檢測并恢復數據處理中的故障,保障服務可用性。
挑戰: 需要較高的自動化與工具鏈投入;對團隊的文化轉變和技能組合(既懂開發又懂運維)要求較高;數據安全與合規在高速自動化流程中需精心設計。
四、數據驅動的開發模式:以數據流為核心的架構演進
這是一種新興的、專門針對數據密集型系統的開發范式。它強調以數據流作為系統設計的核心,架構(如Lambda架構或Kappa架構)圍繞數據的產生、采集、處理、存儲和消費來演進。開發過程本身也深度依賴數據監控和A/B測試來驅動決策。
應用場景:
- 大規模實時流處理系統: 如欺詐檢測、物聯網傳感器數據分析,要求低延遲和高吞吐。
- 個性化推薦引擎: 需要持續從用戶交互數據中學習并即時更新模型。
優勢: 架構與業務的數據流高度契合,性能與擴展性優化更好;開發決策基于實際數據指標而非假設,產品迭代更科學。
挑戰: 對數據工程能力要求極高;需要復雜的技術棧支持(如Flink, Spark Streaming);初期架構設計難度大,需要前瞻性規劃。
與選擇建議
沒有一種模式是放之四海而皆準的。選擇哪種開發模式,取決于數據處理服務項目的具體特性:
- 選擇瀑布模式: 當項目需求絕對穩定、法規合規性要求嚴格,且數據質量與過程的可審計性為第一要務時。
- 選擇敏捷開發: 當業務需求探索性強、變化快,需要與業務部門緊密協作,并追求快速交付數據洞察價值時。
- 選擇DevOps: 當數據處理服務需要高頻率、高可靠性的更新與發布,并且系統復雜到必須依賴自動化來管理時。
- 選擇數據驅動模式: 當構建的是核心的、以實時或近實時數據流為生命線的創新型數據產品時。
在實踐中,混合模式也日益常見。例如,可以采用“敏捷+DevOps”的組合來開發現代數據平臺,在快速迭代的同時保證運維的自動化與穩定性。關鍵在于理解每種模式的精神內核,并將其與項目的數據特性、團隊能力和業務目標靈活匹配,從而構建出高效、健壯的數據處理服務體系。